
“龙虾款”切换本地模型指南
零刻预装 OpenClaw+ 本地模型的机型是通过 llama.cpp 运行本地模型,支持自行新增或删除本地模型。
本教程以零刻 GTR9Pro 「预装 OpenClaw」机型为例,实际上手操作切换本地模型,只需按如下步骤操作即可。
本教程仅适用于预装OpenClaw+本地模型的零刻产品
1. 下载模型
llama.cpp 使用 GGUF 格式的模型文件,建议通过以下两种方式下载模型:
-
Hugging Face(需科学上网)
-
(魔塔社区)
这里我们使用魔塔社区下载 Qwen3.6-35B-A3B-UD-Q8_K_XL.gguf 模型,这是一个高阶 8 位量化版本,精度损耗极低,兼顾优质推理能力与合理显存占用,适配本地部署日常使用。
请根据主机实际配置选择合适的模型。
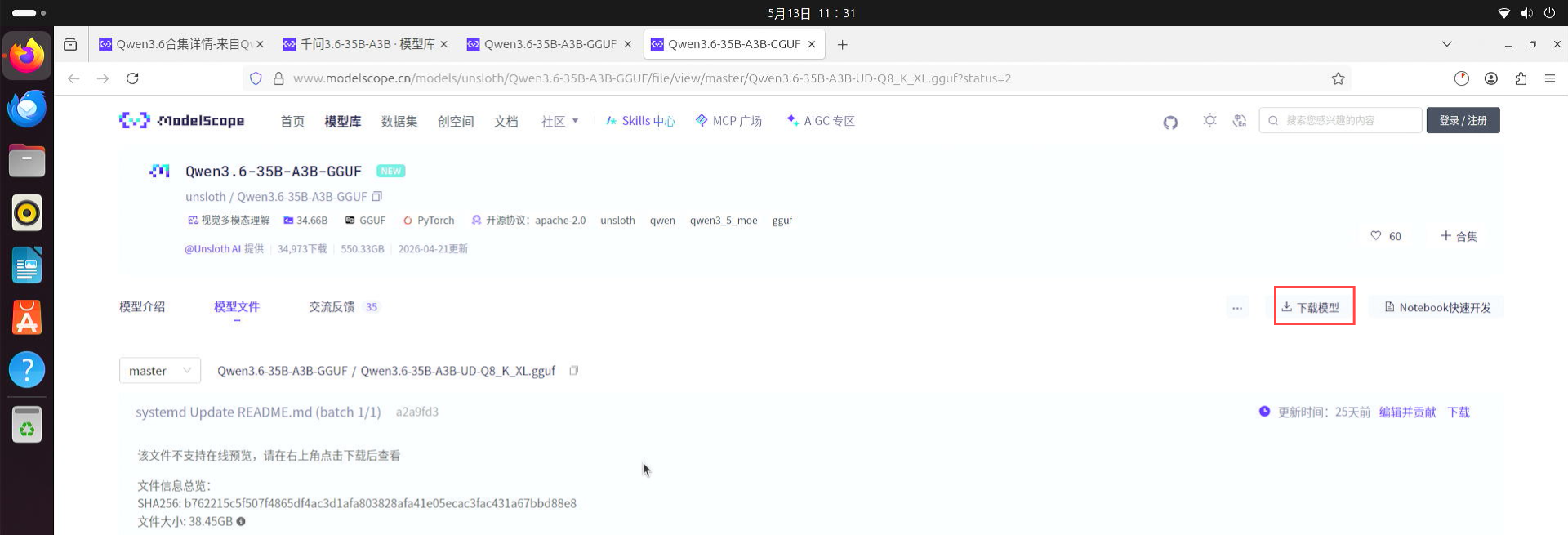
下载好以后,执行以下命令将模型剪切至本地模型目录:
sudo mv /home/用户名/下载/Qwen3.6-35B-A3B-UD-Q8_K_XL.gguf /opt/models/
注:在终端输入密码默认不会显示,正常输入后回车执行即可
剪切后验证是否剪切成功,执行:
sudo ls /opt/models/
输出结果中包含文件(Qwen3.6-35B-A3B-UD-Q8_K_XL.gguf),说明剪切成功。
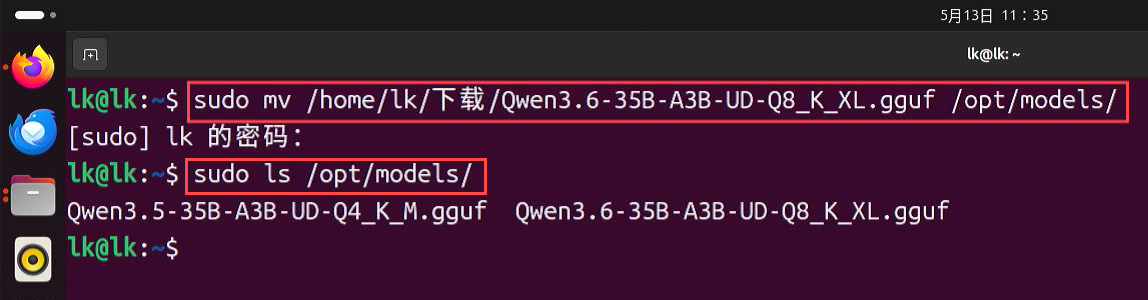
2. 编辑 llama 启动脚本
保存好本地模型后,需要手动编辑 llama 启动脚本,执行:
sudo nano /usr/local/bin/start-llama.sh
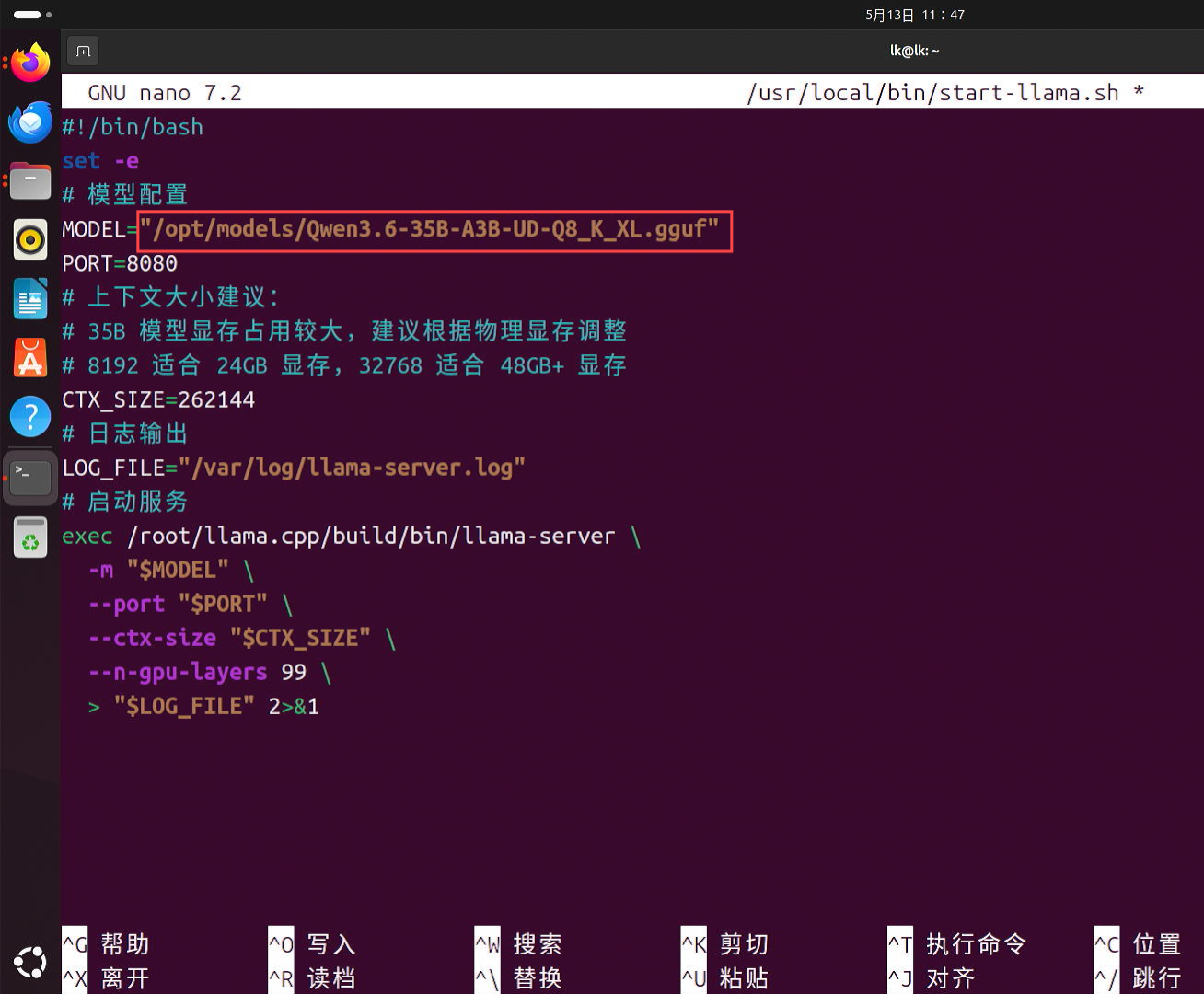
修改 MODEL 字段,将后面双引号中的模型名称改为新的模型名称,其他不用修改。
编辑完成后,按下 Ctrl+X - Y - 回车 ,保存退出编辑器。
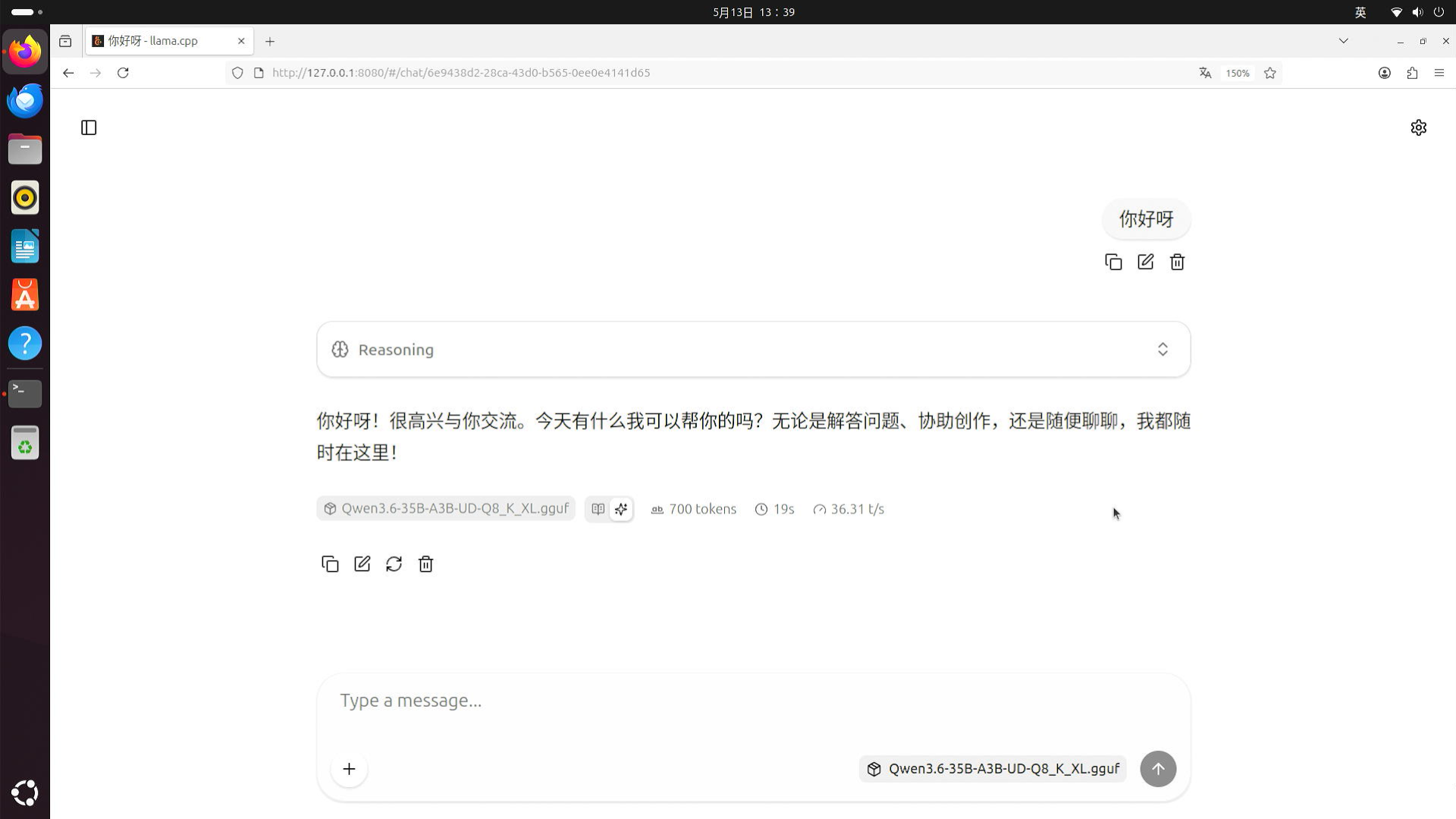
3. 验证新模型是否启用
编辑并保存好 llama 启动脚本后,重启一下系统:
reboot
重启后打开网页 127.0.0.1:8080 ,可以看到显示的模型名称为 Qwen3.6-35B-A3B-UD-Q8_K_XL.gguf,说明模型切换成功,打个招呼确认模型能否正常使用,得到回应后说明成功了。
4. OpenClaw 切换新模型
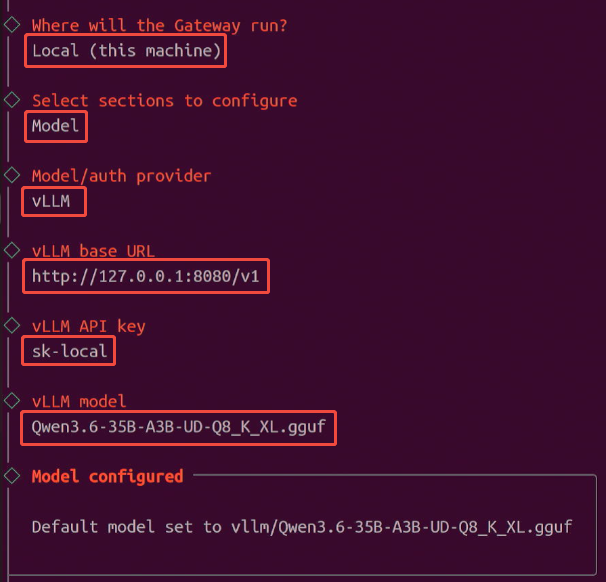
新模型就绪后,还需要到 OpenClaw 中切换默认模型,打开终端执行:
openclaw config
选择 Local - Model
然后选择 vLLM;
vLLM base URL 修改为 http://127.0.0.1:8080/v1;
vLLM API Key 填写 sk-local(可以随意输入)
vLLM model 填写 Qwen3.6-35B-A3B-UD-Q8_K_XL.gguf
然后回车,再按一次回车即可。
这样就配置完成了,再移动到 Continue 并按下回车,结束配置。
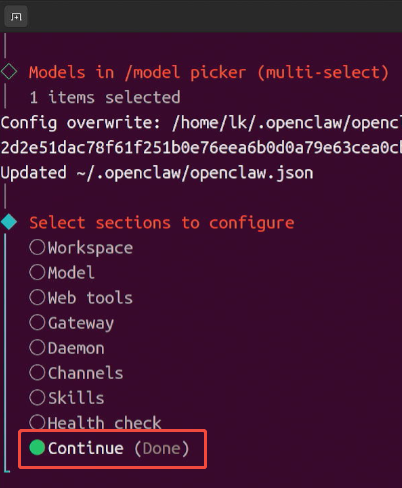
结束配置后,还需要重启 OpenClaw Gateway 以应用修改,执行:
openclaw gateway restart
重启后即可以新模型使用 OpenClaw。
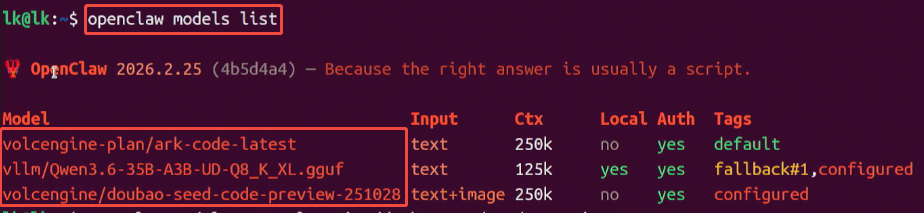
配置好新模型后,原先的模型如果没有取消勾选,会自动以备用模型配置,可以通过以下命令查询可用模型列表:
openclaw models list
在终端中可以切换默认模型,无需重启 Gateway,执行:
openclaw models set 模型全称

如需临时切换模型,可以在与 OpenClaw 的对话中回复:/model 模型全称 快速切换,无需重启。

查看显存占用
首先需要下载工具,在终端执行:
sudo apt install mesa-utils
安装成功后,再次执行:
glxinfo | grep -i "video memory\|vram"
即可查看当前显存情况
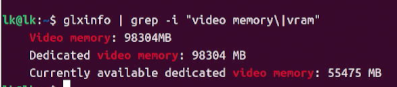
Video Memory:总显存容量
Currently available dedicated video memory:剩余可用显存
Qwen3.6-35B-A3B 模型支持关闭思考模式。
如需关闭思考模式(可提高回复速度),可以在最底下的 "--n-gpu-layers 99 " 的下方新增一条 --chat-template-kwargs '{"enable_thinking":false}',如图
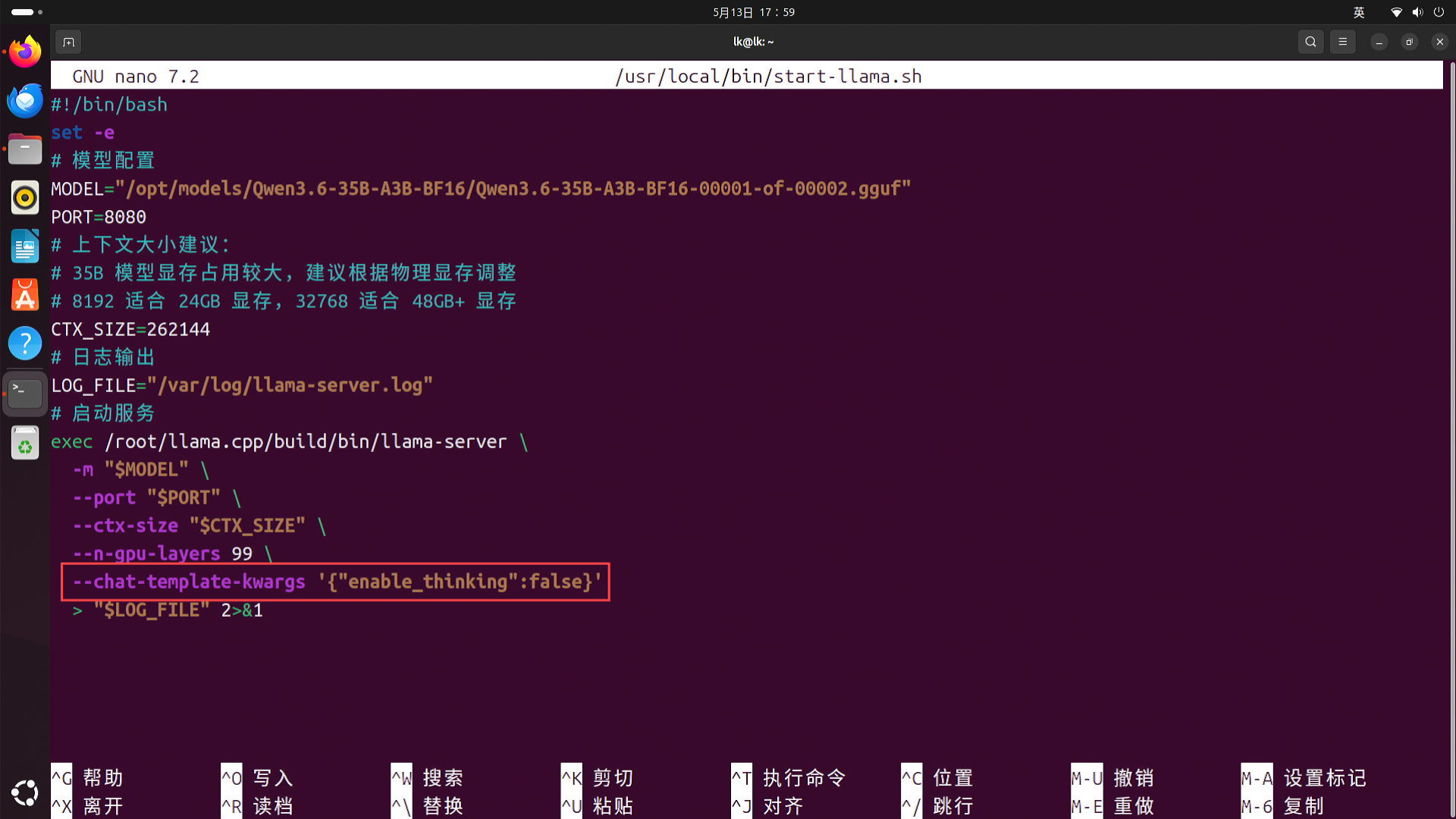
编辑完成后,按下 Ctrl+X - Y - 回车
然后重启系统即可。
No comments to display
No comments to display